




 Artikel
Artikel

Aktives GUI-Element
Statisches GUI-Element
Quelltext
WPS-Objekt
Datei/Pfad
Befehlszeile
Inhalt Eingabefeld
[Tastenkombination]
OS/2 und mehrsprachige Zeichensätze
Teil 2
Dies ist der zweite Artikel aus einer Serie, die einige der Probleme behandelt, die auftreten, wenn man es mit internationalen Texten unter OS/2 zu tun hat. Diese Ausgabe bespricht die Zwei-Byte-Zeichen, die in asiatischen Sprachen wie Chinesisch, Japanisch oder Koreanisch anzutreffen sind.
In meinem letzten Artikel habe ich verschiedene Möglichkeiten aufgezeigt, wie man sich Texte unter OS/2 mit verschiedenen Ein-Byte-Zeichensätzen anzeigen lassen kann. Wie beschrieben, wenn man einen Text mit einem Zeichensatz ansehen möchte, der von der Zeichenumsetzungstabelle des Systems nicht unterstützt wird, kann man diesen normalerweise korrekt anzeigen lassen, wenn man die Zeichenumsetzungstabelle ändert.
Man kann den Prozeßzeichensatz, den PM-Zeichensatz oder beide zusammen ändern. Das Ändern des Prozeßzeichensatzes funktioniert in großem Umfang (zum Beispiel auch beim Drucken), aber es ist eben beschränkt auf die zwei Zeichenumsetzungstabellen, die in der CONFIG.SYS festgelegt sind. Das Ändern des PM-Zeichensatzes funktioniert nur in der GUI-Umgebung (und kann wegen eines obskuren OS/2-Bugs die Arbeit unkontrolliert einstellen), hat aber den Vorteil, daß man unmittelbar eine riesige Zahl an Zeichensätzen zur Verfügung hat, ohne daß man sein System neu einstellen muß.
Beide Methoden arbeiten recht zufriedenstellend, solange man es mit Ein-Byte-Zeichensätzen zu hat, in denen ein Zeichen genau einem Ein-Byte-Wert entspricht.
Aber, was passiert, wenn man es mit Zeichensätzen zu tun hat, die hunderte oder tausende (oder sogar zehntausende) unterschiedliche Zeichen umfassen, und ein Ein-Byte-Wert (der 256 Zeichenelemente abdeckt) nicht ausreicht, um alle darzustellen? Dies trifft insbesondere auf verschiedene ostasiatische Schriftsysteme zu: Chinesisch, Japanisch und Koreanisch, die sogenannten CJK-Zeichensätze.
Wie man jetzt möglicherweise schon ahnt, ändern sich die Spielregeln nachhaltig, wenn ein Ein-Byte-Wert nicht mehr ausreicht, um ein einzelnes Zeichen darzustellen.
DBCS und Mehr-Byte-Verschlüsselung
Um solch große Zeichensätze abzudecken ist es notwendig, jedes Zeichen mit zwei Byte statt nur mit einem Byte darzustellen. Diesen Ansatz kennt man auch als Double-Byte-Character-Set (DBCS)-Verschlüsselung.
Das Problem ist natürlich, daß sie immer noch Kompatibilität mit den bestehenden Zeichensätzen bewahren müssen, die auf einer Ein-Byte-Verschlüsselung aufbauen. Dies wird ermöglicht durch ein Schema, welches üblicherweise als Mehr-Byte-Verschlüsselung bekannt ist.
Mehr-Byte-Verschlüsselung beinhaltet, das Text aus einer Mischung von Ein-Byte- und Zwei-Byte-Zeichen besteht. (Tatsächlich lassen neuere Verschlüsselungen wie etwa UTF-8 sogar Drei- oder Vier-Byte-Zeichen zu.) Dies wird manchmal auch als "Variable-Längen-Verschlüsselung" bezeichnet.
In anderen Zusammenhängen, üblicherweise in Programmierhandbüchern, findet man den Begriff "Mehr-Byte" als Umschreibung für jeden Datenstrom der eine Byte-basierte Verschlüsselung verwendet (im Gegensatz zu Verschlüsselungen, die auf kurzen oder langen ganzen Zahlen basieren und einzelne Zeichen darstellen). Die letztere Verwendung des Begriffs beinhaltet daher sowohl Ein-Byte- als auch Variable-Längen-Verschlüsselungen.
In diesem Artikel werde ich jedoch den Begriff 'Mehr-Byte" verwenden, wenn ausdrücklich Variable-Längen-Verschlüsselungen gemeint sind.

Abbildung 1: Zeichenumsetzungstabelle 932 (Japanisch) – Ein-Byte-Zeichen-Werte
Wie sonst auch hat jeder CJK-Zeichensatz seine eigene Zeichenumsetzungstabelle. Die übliche PC-Zeichenumsetzungstabelle für Japanisch ist zum Beispiel Zeichentabelle 932. Diese Zeichenumsetzungstabelle beinhaltet die üblichen ASCII-Zeichen bei den Zeichenelementen 0x20 bis 0x7E, mit zwei Unterschieden: der Backslash wird durch das Yen-Symbol (¥) ersetzt und die Tilde durch den Oberstrich (¯).
Wie üblich steht der Präfix "0x" für die Zahlen in hexadezimaler Schreibweise. Also "0x20" heißt "hexadezimaler Wert 20".
Ebenso hat sie bei den Zeichenelementen 0xA0 bis 0xDF einen kleinen Satz japanischer Zeichen, welche auch als halbweite Katakana-Zeichen bekannt sind, und umfassen das absolut notwendige Minimum an Zeichen, die benötigt werden, um japanischen Text phonetisch zu schreiben. (Anfangs war dies tatsächlich die einzige Möglichkeit auf Computern Japanisch zu schreiben.) Dann sind da noch ein paar verschiedene Symbole im Bereich unterhalb 0x20. Alle diese sind Ein-Byte-Zeichen, das heißt, sie sind alle ähnlich den lateinischen oder russischen Texten, wie in meinem letzten Artikel besprochen, mit einem einzelnen Byte-Wert verschlüsselt.
Daraus folgt, das die Zeichentabelle 932 mehr oder weniger mit ASCII-verschlüsselten Texten kompatibel ist. Allerdings enthält diese Umsetzungstabelle auch einige spezielle Zeichenelemente: 0x81 bis 0x9F und 0xE0 bis 0xFC (als DB in Abbildung 1 ausgewiesen). Diese Werte werden als Lead Byte verwendet, die auf Zwei-Byte-Zeichen hinweisen.
In dieser Zeichenumsetzungstabelle wird, wann immer man auf eines dieser Lead Bytes trifft, dies selbst nicht als Zeichen interpretiert, sondern als erstes Byte eines Zwei-Byte-Wert-Zeichens. Mit anderen Worten, dieses Byte wird zusammen mit dem nächsten Byte gelesen, um ein Zeichen zu ergeben.
Zeichenumsetzungstabelle 932 hat 60 dieser speziellen Zeichenelemente, mit denen sich (in Verbindung mit dem nachfolgenden Byte) bis zu jeweils 256 zusätzliche eindeutige Zeichen darstellen lassen - obwohl tatsächlich nicht alle Wertekombinationen verwendet werden.

Abbildung 2: Einige Zwei-Byte-Wert-Zeichen definiert in der Zeichenumsetztabelle 932
Abbildung 2 zeigt die Zwei-Byte-Zeichen für 2 Zeichenelemente: 0x82 und 0x90. Wie man sieht, sind nicht alle Werte im 2ten Byte belegt - zum Beispiel die Zwei-Byte-Werte unter 0x40 sind typischerweise undefiniert (aus welchem Grund auch immer), und einige andere Zeichenelemente hier und da ebenfalls.
Ein Beispiel: das Byte-Paar 0x82A0 der Umsetzungstabelle 932 stellt das Hiragana-Zeichen dar, welches einen "A"-Vokal-Klang darstellt. Mit Zeichentabelle 850 würde dies durch 2 separate Zeichen dargestellt (0x82 und 0xA0):
éá
Mit der Umsetzungstabelle 932 jedoch sollte dies richtig als (einzelnes) japanisches Zeichen angezeigt werden.
あ
Dies unterstellt natürlich, daß die eingesetzte Schriftart einen Glyphen für dieses Zeichen enthält (ansonsten würde ein Ersatzzeichen angezeigt, wie in meinem letzten Artikel beschrieben).
Wenn man sich Abbildung 2 ansieht, fragt man sich, wofür diese seltsamen großen lateinischen Zeichen gut sind. Die meisten CJK-Zeichen haben ein (quadratisches) Seitenverhältnis von ungefähr 1:1 (mit anderen Worten, sie passen recht genau in ein Quadrat, wenn sie richtig geschrieben sind) und werden daher in einer festen Zeichenbreite dargestellt. Da die meisten Schriftarten mit fester Zeichenbreite den Zeichen nur einen relativ schmalen rechteckigen Raum zuweisen, werden die CJK-Zeichen üblicherweise so dargestellt, daß sie 2 Zeichenstellen einnehmen statt einer. Dies hat den Vorteil, daß zusätzlicher Platz für diese großen, komplexen Glyphen zur Verfügung steht, während die Zeichen mit fester Zeichenbreite noch richtig aufgestellt sind.
Allerdings, schmaler lateinischer Text (oder anderer Ein-Byte-Text) gemischt mit diesen extrabreiten CJK-Zeichen sieht meist etwas komisch aus, insbesondere innerhalb eines Wortes (wie Name oder Titel). Es scheint ziemlich üblich zu sein, in solchen Fällen extrabreite lateinische Zeichen zu verwenden. Daher enthalten CJK-Zeichensätze und -Schriftarten meist zwei Byte - doppelt breite Versionen der üblichen lateinischen oder anderen Ein-Byte-Zeichen.
Mehr-Byte-Zeichenumsetzungstabellen
Die wichtigsten Mehr-Byte-Zeichentabellen, die in OS/2 als Prozeßzeichensatz unterstützt werden, sind nachfolgend gelistet.
932 Japan Shift_JIS-1990 (Japanisch)
949 Korea KS-Code (Koreanisch)
950 Taiwan Big-5 (Traditionelles Chinesisch)
1381 China GB (Vereinfachtes Chinesisch)
1386 China GBK (Vereinfachtes Chinesisch)
Eine weitere japanische Zeichentabelle, die häufig genutzt wird, ist die 943, die der 932 sehr ähnlich ist, aber nur als PM-Zeichensatz verwendet werden kann (tatsächlich ist die 932 nur eine andere Bezeichnung für die 943, aber COUNTRY.SYS läßt nur die erstgenannte zur Angabe des Prozeßzeichensatzes zu). Dann gibt es auch noch Zeichentabelle 942, die den nur geringfügig älteren (gleichwohl nahezu identischen) Shift_JIS-1978 Japanisch-Zeichensatz umsetzt. Auch dieser ist nur als PM-Zeichensatz verfügbar.
Die "Vereinfachtes Chinesisch"-Zeichentabelle 1381 basiert auf dem GB2312-Zeichensatz und ist für gewöhnlich die Standardzeichentabelle für "Vereinfachtes Chinesisch"-OS/2-Zeichentabelle 1386 und setzt den neueren GBK-Standard um.
Die koreanische Zeichenumsetzungstabelle 949 unterstützt den KSC5601-1992-Zeichenstandard ("Wansung"-Verschlüsselung). Es sei darauf hingewiesen, daß auf Windowssystemen die Zeichentabelle 949 tatsächlich einen deutlich erweiterten koreanischen Zeichensatz, bekannt als "Vereinheitlichter Hangul Code" (oder "erweiterter Wansung"), der viele tausend zusätzliche Zeichen hinzufügt, umsetzt. OS/2 kann man aktualisieren, damit diese erweiterte Zeichentabelle 949 unterstützt wird, indem man die Datei \LANGUAGE\CODEPAGE\IBM949 auf dem Systemlaufwerk mit der Version von Ken Borgendales OS/2 Zeichentabellenwerkzeuge ersetzt.
Im ersten Teil dieser Serie gab ich einen Überblick über die wichtigsten Zeichenumsetzungstabellen für verschiedene Gebiete; Zeichentabelle 1381 (China GB) wurde unbeabsichtigt nicht in dieser Liste erwähnt. Ich entschuldige mich für dieses Versehen.
Mehr-Byte-Zeichen betrachten
Nun, was bedeutet dies alles für die Techniken, die ich in meinem letzten Artikel beschrieben habe? Nun, es bringt ein paar zusätzliche Herausforderungen mit sich.
DBCS-fähige Schriftarten
Als erstes (und offensichtlich) benötigt man eine Schriftart, die die Zeichen unterstützt, die man nun verwenden möchte. Letztes Mal war das kein großes Problem, als wir mit den Ein-Byte-Zeichen zu tun hatten, weil die meisten OS/2-Schriftarten Glyphen für viele Ein-Byte-Zeichensätze enthalten. Zum Beispiel enthalten WarpSans, System VIO und Helv Unterstützung für zahlreiche lateinische Alphabete wie auch für Griechisch, Thai, Hebräisch, Arabisch, Kyrillisch und ein paar andere. Jedoch enthält keine dieser Schriftarten Glyphen für auch nur ein Zwei-Byte-CJK-Zeichen (außer man verwendet eine der speziellen DBCS-Sprachversionen von OS/2, was ein Sonderfall ist).
Besonders das OS/2-Bitmap-Schriftartenformat unterstützt die Zwei-Byte-Zeichen offenbar gar nicht. Die DBCS-Version von OS/2, wie etwa Japanisch oder Chinesisch, umgehen diese Einschränkung, indem sie einen speziellen Schriftartentreiber verwenden: CJK-Zeichen-Glyphen sind in separaten Dateien enthalten, und verschiedene OS/2-Systemschriftarten können diese dann bei Bedarf laden.
Damit chinesische, japanische oder koreanische Zeichen in einer Ein-Byte-Sprachversion von OS/2 sauber angezeigt werden, braucht man eine mehrsprachige Schriftart, die diese unterstützt. Für gewöhnlich ist dies eine True-Type-Schriftart – Type-1-Schriftarten scheinen irgendwie ziemlich eingeschränkt zu sein, was die Mehrsprachenfähigkeit angeht, und OS/2-Bitmap-Schriftarten unterstützen CJK-Zeichen für gewöhnlich überhaupt nicht (siehe obige Ausführungen).
Wie schon zuvor wettet man am besten auf eine Unicode-Schriftart. Wie ich schon zuletzt bemerkte, sind verschiedenen Unicode-Schriftarten erhältlich, die CJK-Zeichen unterstützen, und OS/2 (beginnend mit dem WarpServer for e-business) bringt sogar einige davon gleich mit.
- Times New Roman WT *
- Eine Unicode-Version der klassischen Times New Roman Proportionalschriftart.
- Monotype Sans Duospace WT *
- Eine attraktive Unicode-Schriftart mit fester Zeichenbreite.
In beiden steht das * für J, K, TC oder SC. Wenn man OS/2 gestattet die Unicode-Schriftarten zu installieren, wird die J-Version installiert (und Times New Roman WT J wird auch als Times New Roman MT 30 ausgewiesen, aus Gründen der Kompatibilität zu Programmen die unter Warp 3 und 4 geschrieben wurden).
Der Zweck des Unciode-Standards ist es, die Unterstützung für alle möglichen Zeichensätze innerhalb eines Zeichenraumes zu ermöglichen. Man fragt sich nun, warum die OS/2-Unicode-Schriftarten in 4 verschiedenen sprachspezifischen Versionen daherkommen.
Japanisch, Koreanisch und die beiden Chinesisch-Varianten verwenden alle die gleichen (chinesisch orientierten) ideografischen Zeichen. Der Unicode-Standard definiert daher nur einen einzigen Satz der CJK-Ideografen (diese werden dann HAN-Zeichen genannt) die für alle 4 Sprachen verwendet werden.
Zwischen Japanisch, Koreanisch und den beiden Chinesisch-Varianten gibt jedoch stilistische Unterschiede darin, wie manche Zeichen gewöhnlich geschrieben werden. IBM beschreibt dies in einem Artikel so:
Es gibt vier grundlegende Brauchtümer in den ostasiatischen Zeichengestaltungen: traditionelles Chinesisch, vereinfachtes Chinesisch, Japanisch und Koreanisch. Mag das Han-Stammzeichen in allen CJK-Sprachen auch gleich sein, die gebräuchlichen Glyphen für das gleiche Zeichen müssen es nicht.
...
Schriftarten sind der Auslieferungsmechanismus für die Glyphenanzeige. Das heißt, daß Han-Zeichen vereinheitlicht wurden, aber dies bei Schriftarten nicht geht. Damit die Glyphenvarianten verfügbar sind, die benötigt werden um den Anforderungen der Schreibsystemunterschiede gerecht zu werden, müssen Schriftarten spezifisch auf das gerade verwendete (Schreib-)System abgestimmt sein. Versuchte man nur eine Schriftart zu verwenden, würden unter Garantie einige Zeichen nicht allen Nutzern als richtig erscheinen.
Es ist wichtig zu verstehen, daß der Unicode-Standard die Identität der Zeichen definiert. Die Erscheinung jedes Zeichens ist dagegen der verwendeten Schriftart (oder den Schriftarten) überlassen.
Aus diesem Grunde hat IBM 4 verschiedene Versionen herausgegeben, jede zugeschnitten auf die jeweilige Sprache.
In meinem letzten Artikel habe ich einige weitere sinnvolle Unicode-Schriftarten beschrieben. Wenn man Zugriff darauf hat, ist Arial Unicode MS recht nett, insbesondere bei Verwendung im Web-Browser.
Sollte Ihre OS/2-Version vor dem WarpServer for e-business datieren, wird Ihnen wärmstens empfohlen, sich die Schriftart "Times New Roman MT 30" zu beschaffen, die in einigen Versionen der IBM Java-1.1.8-Runtime-Umgebung (JAVAINUF.EXE) enthalten ist.
Tatsächlich werden mit dem Java-Runtime-Paket auch aktualisierte Zeichenumsetzungstabellen (und Unicode) und deren Unterstützung in Warp 3 und Warp 4 installiert, so daß man nicht zögern sollte, dieses Paket zu installieren, wenn man eine solche Version sein eigen nennt.
Alternativ dazu hat OS/2 auch einige spezielle (nicht Unicode) Schriftarten für Japanisch und Chinesisch (beide Varianten). Noch mal, dies gilt nur für den WarpServer for e-business und neuere Versionen (einschließlich aller eComStation-Versionen). Man kann sie im Installationsprogramm auswählen oder nachträglich durch Entzippen der entsprechenden Dateien aus dem Verzeichnis \OS2IMAGE\FI\FONT der Installations-CD installieren.
| Sprache | Schriftartname | Dateiname | Bemerkungen |
|---|---|---|---|
| Japanisch | HeiseiMincho-W3-78-TT | DFHSM-78.TTF (aus DFHSM-78.ZIP) | Entwickelt für Shift_JIS-1978 (Zeichenumsetzungstabelle 942) |
| HeiseiMincho-W3-90-TT | DFHSM-W3.TTF (aus DFHSM-W3.ZIP) | Entwickelt für Shift_JIS-1990 (Zeichenumsetzungstabellen 932 & 943) | |
| HeiseiKakuGothic-W5-78-TT | DFHSG-78.TTF (aus DFHSG-78.ZIP) | Entwickelt für Shift_JIS-1978 (Zeichenumsetzungstabelle 942) | |
| HeiseiKakuGothic-W5-90-TT | DFHSG-W5.TTF (aus DFHSG-W5.ZIP) | Entwickelt für Shift_JIS-1990 (Zeichenumsetzungstabellen 932 & 943) | |
| Vereinfachtes Chinesisch | 仿宋常规 | IBMFANG.TTF (aus IBMFANG.ZIP) | Der Name erscheint als "À┬╦╬│ú╣µ" mit Zeichenumsetzungstabelle 850 |
| 黑体常规 | IBMHEI.TTF (aus IBMHEI.ZIP) | Der Name erscheint als "║┌╠Õ│ú╣µ" mit Zeichenumsetzungstabelle 850 | |
| 楷体常规 | IBMKAI.TTF (aus IBMKAI.ZIP) | Der Name erscheint als "┐¼╠Õ│ú╣µ" mit Zeichenumsetzungstabelle 850 | |
| [婳S^8壞 | IBMSONG.TTF (aus IBMSONG.ZIP) | Offensichtlich entwickelt für GBK (Zeichenumsetzungstabelle 1386); Der Name erscheint als "[ïOS^8ë─"mit Zeichenumsetzungstabelle 850 |
|
| Traditionelles Chinesisch | 中黑體 | HEI.TTF (aus HEI.ZIP) | Der Name erscheint als "ññÂ┬┼Ú" mit Zeichenumsetzungstabelle 850 |
| 標準楷體 | MOEKAI.TTF (aus MOEKAI.ZIP) | Der Name erscheint als "╝ðÀÃÀó┼Ú" mit Zeichenumsetzungstabelle 850 | |
| 標準宋體 | MOESONG.TTF (aus MOESONG.ZIP) | Der Name erscheint als "╝ðÀú║┼Ú" mit Zeichenumsetzungstabelle 850 |
Jede Schriftart kann nur eingesetzt werden, um Texte in der entsprechenden Sprache anzuzeigen. Nebenbei bemerkt, ich empfehle diese Schriftarten nicht mit dem Mozilla einzusetzen: nach meiner Erfahrung funktionieren sie nicht sonderlich gut mit der Innotek Font Engine. Außerdem ist ihre Unterstützung für lateinische Texte ziemlich dürftig (wegen mangelndem Verständnis nehme ich an). Ich vermute, sie sind wirklich nur für DBCS-Glyphen gemacht und nichts anderes.
Zeichen-Ersetzung
Es gibt noch einen anderen Weg, CJK-Zeichen auf ihrem System zur Anzeige zu bekommen, ohne ausdrücklich eine Schriftart einzusetzen. Der Presentationsmanager hat eine ungewöhnliche Funktion, die "Schriftartenassoziation" genannt wird, mit deren Hilfe er automatisch solche Zeichen ersetzen kann, die in der aktuellen Schriftart nicht existieren.
Es funktioniert wie folgt: In der OS2.INI gibt es den Abschnitt PM_SystemFonts. Wenn dieser Abschnitt einen Schlüssel namens PM_AssociateFont enthält, der den Namen einer installierten Schriftart spezifiziert, dann wird der Presentationsmanager (wann immer er auf ein Zeichen trifft, daß in der aktuellen Schriftart nicht verfügbar ist) versuchen, dieses durch einen entsprechenden Glyphen aus der angegebenen Schriftart zu ersetzen.

Abbildung 3: Nicht unterstützte Zeichen
Sagen wir mal, als Beispiel, wir möchten den Ausdruck "Japanese (日本語)" anzeigen in einer grafischen Umgebung, die die System Proportional-Schriftart verwendet. Diese Schriftart unterstützt nicht eines der japanischen Zeichen, die in dem Ausdruck verwendet werden, so daß – wenn wir auf Zeichensatz 932 oder 943 umgeschaltet haben – er normalerweise mit Ersatzsymbolen dargestellt wird wie Abbildung 3 zeigt.
Dann jedoch, sagen wir mal, legen wir mit dem PM_AssociateFont-Schlüssel die Anwendung der japanischen HeiseiMincho-W3-90-TT-Schriftart fest. Jeder INI-Datei-Editor kann verwendet werden, einschließlich des mitgelieferten OS/2-Registry-Editors, wie in Abbildung 4 zu sehen ist.
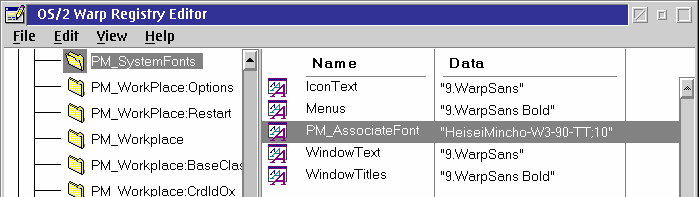
Abbildung 4: Der PM_AssociateFont-Schlüssel
In diesem Beispiel haben wir den Wert HeiseiMincho-W3-90-TT;10 dem Schlüssel PM_AssociateFont zugewiesen. Es scheint erforderlich zu sein ";10" hinter dem Namen der Schriftart zu plazieren. (Kann sein, das es irgendwie auf die Schriftgröße hinweist; ich bin mir jedoch nicht sicher, welchen Zweck dies haben soll, da alle ersetzten Glyphen ohnehin so angepaßt werden, daß sie in der Größe der aktuellen Schriftart entsprechen.)
Damit diese Änderung wirksam wird, muß das System neu gestartet werden.

Abbildung 5: Nicht unterstützte Zeichen
mit aktivierter Assoziation
Wenn man jetzt versucht, den gleichen GUI-Text anzeigen zu lassen (mit Zeichentabelle 932 natürlich), sollten die fehlenden Zeichen aus der japanischen Schriftart ersetzt werden, wie Abbildung 5 zeigt.
Diese Technik ist nicht perfekt. Der PM scheint ziemlich wählerisch zu sein, was die Schriftart angeht; bei meinen Versuchen akzeptierte er keine Unicode-Schriftart (noch nicht einmal die von OS/2 mitgelieferten). Im allgemeinen sollte man eine der OS/2-Schriftarten einsetzen, die in Tabelle 1 angegeben ist. Dies bedeutet, unglücklicherweise, daß man diese Technik nur für eine bestimmte Sprache oder einen bestimmten Zeichensatz einsetzen kann.
Außerdem funktioniert diese Technik nur mit Texten in der grafischen Benutzerschnittstelle (GUI).
Ändern der Zeichenumsetzungstabelle
Außer daß man die richtige Schriftart haben muß, muß man auch die Zeichenumsetzungstabelle richtig einstellen, damit die Zeichen richtig erscheinen. Im Prinzip funktioniert dies wie in meinem letzten Artikel beschrieben, aber es gibt da ein paar neue Hürden.
Ändern de PM-Zeichensatzes
Für PM-Applikationen kann man den PM-Zeichensatz durch das CPPal-Hilfsmittel ändern (oder in der Anwendung selbst, soweit vorgesehen), wie zuletzt beschrieben. Unglücklicherweise funktioniert diese Technik bei Mehr-Byte-Zeichenumsetzungstabellen nicht so reibungslos wie bei Ein-Byte-Zeichentabellen.
Das Problem tritt auf, wenn die Anwendung mit einer Ein-Byte-Prozeßzeichentabelle gestartet wird (wie in der CONFIG.SYS festgelegt). Wenn dies so ist, müssen die Steuerelemente der grafischen Benutzerschnittstelle der Anwendung davon ausgehen, daß es sich um Ein-Byte-Text mit Zeichen in der Standardbreite handelt; ein plötzlicher Wechsel mittendrin zu einer Mehr-Byte-PM-Zeichentabelle ist nichts, womit sie umgehen können, und auch nicht dafür geschrieben wurden.
Was dann passiert ist, daß die PM-Elemente, die die direkte Textmanipulation unterstützen – Eingabefelder und MLE (Editor)-Elemente im besonderen –, durcheinander geraten, wenn sie doppelt breite (Doppelbyte-Zeichen) darstellen sollen. Das genaue Erscheinungsbild dieses Problems scheint dabei ziemlich von der eingestellten Schriftart abhängig zu sein. Wenn man eine Unicode-Schriftart fester Breite wie Monotype Sans Duospace WT J einsetzt, ist die Textausgabe mehr oder weniger korrekt, aber die Texteingabe ist wahrscheinlich völlig zerstreuselt. Setzt man eine proportionale Schriftart, eine Nicht-Unicode-Schriftart fester Breite oder irgendeine ander Schriftart in Verbindung mit der PM_AssociateFont-Schriftartersetzung ein, werden die Zeichen wahrscheinlich leicht übereinander geschoben ausgegeben – was in einem inakzeptablen Wirrwarr sich überlagernder Zeichen resultiert. In beiden Fällen sind die Cursorbewegungen und -positionierungen wahrscheinlich auch fehlerhaft.
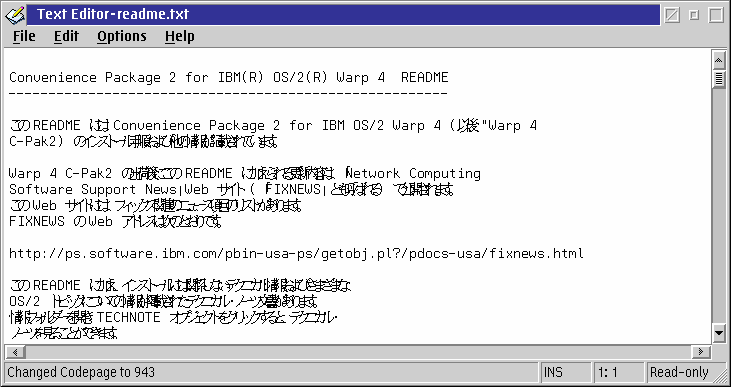
Abbildungen 6 und 7 zeigen die README.TXT-Datei von der japanischen MCP2-CD-ROM mit einem MLE-basierenden Texteditor (AE). In beiden Fällen wurde der Editor zuerst unter Zeichentabelle 850 (eine Ein-Byte-Zeichentabelle) gestartet, und dann wurde die PM-Zeichentabelle auf 943 gesetzt (eine japanische Mehr-Byte-Zeichentabelle, identisch zur 932).
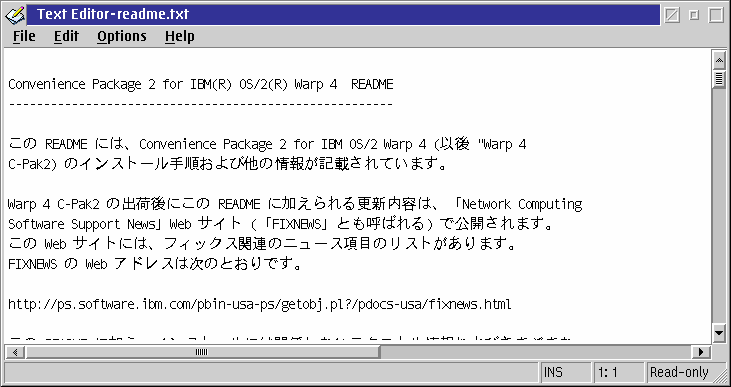
Figure 7. Ändern des PM-Zeichensatzes mit MLE-Elementen (bei Verwendung einer Unicode-Schriftart mit fester Breite) [Großes Bild]
In Abbildung 6 verwendet der Editor seine Standardschriftart (Bitmap) und verläßt sich auf die PM_AssociateFont-Glyphenersetzung, um die japanischen Zeichen anzuzeigen. In Abbildung 7 wurde die Editorschriftart auf die Unicodeschriftart mit fester Zeichenbreite Monotype Sans Duospace WT J eingestellt.
Wie man erkennt, sind in Abbildung 6 die Zwei-Byte-Zeichen überlappend und nicht lesbar. Die Zeichen werden in Abbildung 7 richtig angezeigt, aber die Cursorpositionierung ist nicht in Ordnung (nicht erkennbar). Wenn man Abbildung 7 weiter untersucht, fällt auf, daß der horizontale Schiebebalken aktiviert wurde, obwohl der Text horizontal problemlos in das Fenster paßt; dies ist ein weiteres Symptom für die Fehler in der MLE-Steuerung bei der Breitenberechnung der Zeichen.
Abgesehen davon, statische Kontrollelemente wie Knöpfe und Hinweistexte scheinen dieses Problem nicht zu haben, ebenso Listenkästen und Container. Dies liegt wohl daran, daß diese Elemente angelegt sind Text nur auszugeben und nicht zur Bearbeitung bereitzustellen.
Abbildung 8 zeigt, wie diese statischen Elemente den Mehr-Byte-Text tatsächlich korrekt anzeigen können. Wie gehabt, das Programm wurde unter Zeichenumsetzungstabelle 850 gestartet, und dann wurde die Zeichentabelle auf 943 mittels CPPal geändert (Schriftartenassoziation aktiviert).

Ändern der Prozeßzeichenumsetzungstabelle
Diese Probleme können für gewöhnlich umgangen werden, wenn das Programm gleich unter einer Mehr-Byte-Zeichentabelle gestartet wird. Dies setzt natürlich voraus, daß eine Mehr-Byte-Zeichenumsetzungstabelle als erste oder zweite Zeichentabelle in der CONFIG.SYS eingestellt ist.
Da ich recht häufig mit CJK-Texten arbeite, steht in meiner CONFIG.SYS:
CODEPAGE=850,932
Damit kann ich japanischen Text in einer PM-Anwendung verwenden, indem ich CHCP 932 in einem OS/2-Befehlszeilenfenster aufrufe, bevor ich das Programm starte. Da das Programm schon von Anfang an auf eine Mehr-Byte-Zeichentabelle ausgerichtet ist, treten die beschriebenen Anzeigeprobleme erst gar nicht auf.
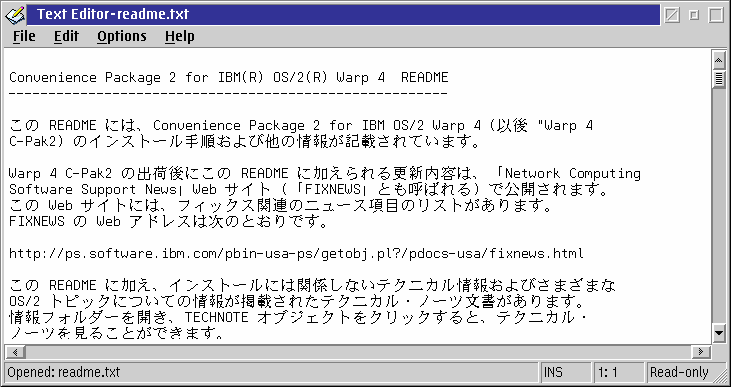
Zurück zum vorherigen Beispiel zeigt Abbildung 9 nun die gleiche japanische Textdatei geöffnet im AE-Editor. Diesmal wurde der AE mit der voreingestellten Prozeßzeichentabelle 932 gestartet. Der AE verwendet meine übliche Bitmap-Schriftart mit Glyphenersetzung aus der "HeiseiMincho-W3-90-TT", aktiviert durch den PM_AssociateFont. Wie man sieht, werden die Zeichen richtig angezeigt, und sogar die Cursorbewegungen sind diesmal so, wie sie sein sollen.
Der beste Nebeneffekt dieser Technik ist, daß man nun nachfolgend nahezu alle anderen Mehr-Byte-Zeichentabellen als PM-Zeichentabelle benutzen kann und die Zwei-Byte-Zeichen dieser Zeichensätze nun auch richtig angezeigt werden. Zum Beispiel kann ich ein GUI-Programm unter Zeichentabelle 932 (Japanisch) starten, dann CPPal einsetzen, um den PM-Zeichensatz auf 950 (traditionelles Chinesisch) zu ändern, und alle PM-Steuerelemente werden die Zwei-Byte-Zeichen weiterhin richtig umsetzen. Das wichtigste scheint dabei zu sein, daß man mit einer Mehr-Byte-Zeichentabelle startet – irgendeiner Mehr-Byte-Zeichenumsetzungstabelle. Dann kann man den PM-Zeichensatz auf verschiedene andere Mehr-Byte-Zeichentabellen ändern, ohne daß man auf die Probleme trifft, die im vorherigen Abschnitt beschrieben sind.
Ich weiß zwar nicht zuverlässig, ob dies mit allen CJK-Zeichensätzen funktioniert, aber ich setze diese Technik erfolgreich ein, um zwischen Japanisch und Chinesisch hin- und herzuschalten.

Abbildung 10: Einstellen der Standardzeichenumsetzungstabelle eines Programmobjektes
Aus diesem Grunde, wenn man also häufiger mit Texten oder Programmen arbeitet, die Zwei-Byte-Zeichen enthalten, ist es keine schlechte Idee, die zweite Zeichenumsetzungstabelle (in der CONFIG.SYS) auf die Mehr-Byte-Zeichenumsetzungstabelle einzustellen, die man am häufigsten benutzt. Man kann dann nämlich Zwei-Byte-Text in den PM-Applikationen anzeigen lassen, indem man sie aus einer Befehlszeile heraus startet, deren Prozeßzeichensatz zuvor auf diese zweite Zeichentabelle umgeschaltet wurde.
Mit dem OS/2-WarpServer for e-business oder eComStation/MCP mit den letzten Fixpacks, kann man sogar ein gesondertes Programmobjekt für diesen Zweck einrichten. Man erzeugt einfach ein neues Programmobjekt für die fragliche Anwendung (oder Befehlszeilenobjekt für den eher generellen Einsatz), dann öffnet man das Einstellungsnotizbuch und geht auf den Sprache-Reiter. Wie Abbildung 10 zeigt, kann auf dieser Notizblockseite die Standard-Prozeßzeichentabelle auf die zweite Zeichenumsetzungstabelle setzen (in diesem Beispiel Zeichentabelle 932). Danach wird dieses Programm oder wird die Befehlszeile beim Öffnen immer mit der Zeichentabelle 932 gestartet.
Es ist wichtig festzuhalten, daß selbst wenn man in einer Befehlszeilensitzung auf eine Mehr-Byte-Zeichentabelle gewechselt hat (entweder mittels CHCP oder über den Sprache-Reiter), man Mehr-Byte-CJK-Text nur innerhalb von grafischen PM-Programmen, die aus dieser Befehlszeile heraus gestartet wurden, anzeigen lassen kann. Man kann diese Technik nicht einsetzen, um CJK-Text in der Befehlszeilensitzung selbst anzuzeigen (außer man setzt die DBCS-Version von OS/2 ein). Die Text-Modus-Schriftarten aus OS/2 haben schlichtweg nicht die notwendige Zeichenunterstützung. (In den meisten Fällen sieht man nur irgendwelchen Müll statt der CJK-Zeichen; wie auch immer, ich habe gelegentliche Hänger und Abstürze beobachtet. Aus diesem Grund empfehle ich es noch nicht einmal zu versuchen.)
KShell
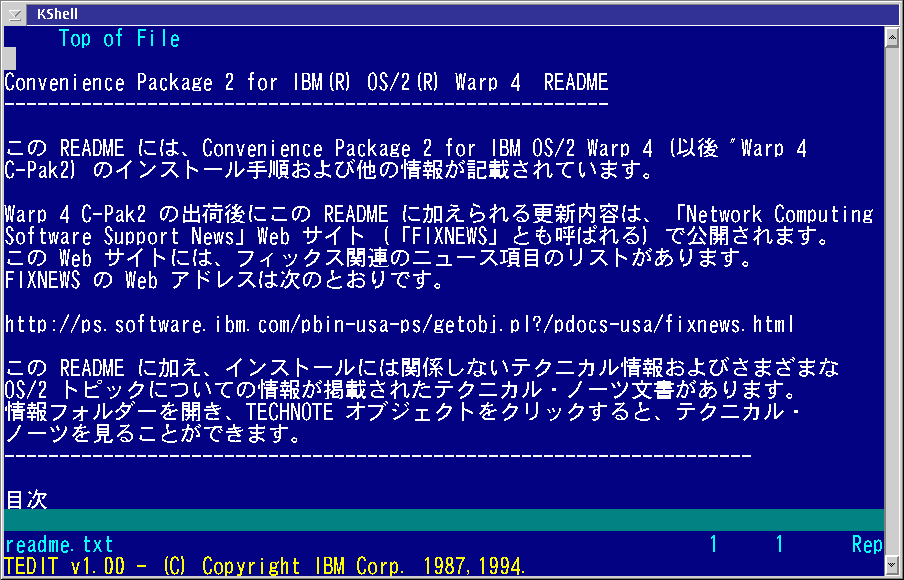
Für alle Leute, die CJK-Zeichen direkt in einer Befehlszeile verwenden müssen, gibt es ein kleines, raffiniertes Programm von KO Myung-Hun names KShell. KShell leitet die VIO-Ausgabe auf eine spezielle Befehlszeile um, die Mehr-Byte-Zeichensätze und -Schriftarten in einer DBCS-Version von OS/2 unterstützt. Abbildung 11 zeigt wiederum die Datei README.TXT des japanischen MCP2, diesmal im TEDIT-Editor.
KShell hat nur zwei einstellbare Optionen: Die Zeichenumsetzungstabelle und die Schriftart. Auf beide kann man über die Systemsteuerung in der linken oberen Ecke zugreifen. Nach meinen Erfahrungen muß man KShell beenden und neu starten, nachdem man die Einstellungen geändert hat, damit die neuen Einstellungen übernommen werden.
KShell ist nicht perfekt! Zum einen hat es eine eingeschränkte Zwischenablagefunktion. Ich hatte gelegentlich auch Fälle, in denen es nicht ordnungsgemäß startete (in diesen Fällen half nur ein Neustart, um das Programm wieder zum Leben zu erwecken). Aber, es kann ein sehr sehr nützliches Programm sein.
Mozilla

Habe ich Sie nun zur Genüge durcheinandergebracht oder eingeschüchtert? Nun, dann beenden wir diesen Artikel mit einer etwas leichteren Kost. Wenn man nur ein paar Textdateien oder andere Dateien, die Mehr-Byte-Text enthalten, anschauen möchte, dann muß man sich nicht durch das gesamte gerade beschriebene Gemenge durchquälen. Wenn man einen Mozilla-Browser installiert hat (Mozilla-Suite, SeaMonkey, IBM WebBrowser oder Firefox), kann man diesen zur Anzeige von Textdateien in fast allen möglichen Zeichensätzen (Ein- oder Mehr-Byte) einsetzen, und er wird sich selber um die Manipulation der Zeichenumsetztabellen kümmern.
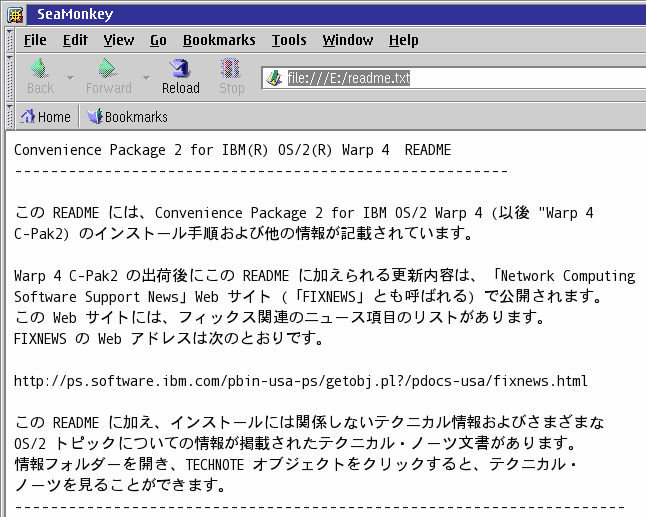
Man muß Mozilla wohl sehr wahrscheinlich mitteilen, welcher Zeichensatz verwendet wird. Im Gegensatz zu HTML-Dokumenten enthalten Nur-Text-Dateien ja keine eingebettete Informationen über den Zeichensatz der bei ihrer Erstellung eingesetzt wurde. Egal, welchen Mozilla-Browser man einsetzt, über das Menü Ansicht > Zeichencodierung kann man Mozilla mitteilen, welchen Zeichensatz er nehmen soll, um das aktuelle Dokument anzuschauen (siehe Abbildung 12, in der wiederum die Datei README.TXT aus dem Japanischen MCP2 dargestellt wird, diesmal angezeigt in SeaMonkey).
Auch hier muß man sicherstellen, daß für den Zeichensatz die richtige Schriftart eingesetzt wird. Dies stellt man für gewöhnlich bei allen Mozilla-Browsern in einer sehr ähnlichen Art und Weise ein (obwohl der genaue Ort und das Erscheinungsbild der Dialoge voneinander abweichen kann). Der Schriftarten-Einstellungsdialog sollte ein Listenfenster für die Sprachen besitzen, und zu jeder Sprache müssen dann die Schriftarten festgelegt werden, die den Zeichensatz der jeweiligen Sprache unterstützen.
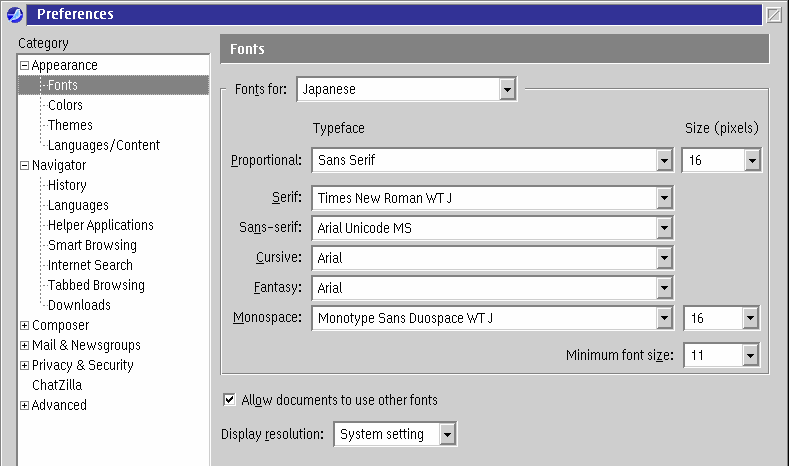
Abbildung 13 zeigt den Schriftarten-Einstellungsdialog in SeaMonkey. In dem Beispiel wurden die Schriftarten für Japanisch konfiguriert. Mit dieser Konfiguration kann man nun die Zeichencodierung auf Japanisch umschalten (wie in Abbildung 12) und die Inhalte sollten richtig angezeigt werden. Abbildung 14 zeigt das Endergebnis.
{kind=link}
Schlußbemerkung
An dieser Stelle hoffe ich, daß ich einen recht guten Überblick über die Probleme im Umgang mit Dateien und Benutzerschnittstellen, die inkompatible Zeichensätze verwenden, gegeben habe. Es ist nicht gerade eine leichte Kost, aber im allgemeinen kann man damit umgehen – unter Zuhilfenahme von ein paar wenigen einfachen Werkzeugen und Techniken.
Auf eine Sache bin ich noch nicht im Detail eingegangen, nämlich die Problematik der E-Mail- und Newsgruppen-Nachrichten. Auch hier nehmen die Mozilla-Produkte einem wiederum die meisten der Probleme ab; verwendet man jedoch eine andere Usenet- oder E-Mail-Software, fühlt man sich durchaus zurückgesetzt, wenn man es mit verschiedenen Zeichensätzen zu tun hat. Hoffentlich kann ich in naher Zukunft mehr darüber erzählen.
Und dann ist da, natürlich, Unicode, ein Thema das alleine schon Buchbände füllen kann. Vielleicht habe ich auch die Möglichkeit dieses Thema zu streifen.
Wie dem auch sei, bis dahin… viel Glück.